Python
内置函数
# 查看所有内置函数和常量
import builtins
print(dir(builtins))
# 常见内置函数分类
"""
数学相关: abs, pow, round, sum, min, max, divmod
类型转换: int, float, str, bool, list, tuple, dict, set, bytes
可迭代对象: len, range, enumerate, zip, map, filter, sorted, reversed
输入输出: print, input, open
对象属性: type, isinstance, issubclass, hasattr, getattr, setattr
其他: id, hash, chr, ord, bin, hex, oct, eval, exec, compile
"""
虚拟机
virtualenv
# 安装虚拟机
pip install virtualenv
# 创建虚拟机
virtualenv -p python3 venv
# 激活虚拟机
source venv/bin/activate
# 退出虚拟机
deactivate
venv原生?
python3 -m venv /Users/macos/pyenv
source ~/pyenv/bin/activate
# 退出
deactivate
还有pyenv等
tips
arr = [1,2,3]
dir(arr) # 列出变量所指对象的所有方法
type(arr) # 打印变量的类型
arr[::-1] # 倒序
arr[0,3,2] # 即为:arr.__getitem__(slice(None,3,2))
a = (123) # 想定义为tuple,结果成了int
a = (123,) # 这才是定义一个元素是元组
a = 1, 2 # 这也是定义一个元组(因为不可更改)
# 利用set来给list去重
list_a = [1,2,3,3]
list_b = list(set(list_a))
[item for item in range(10) if item % 3 == 0] # [0,3,6,9]
# 判断类型是否合适
if isinstance(x, (int, float)):
pass
迭代器
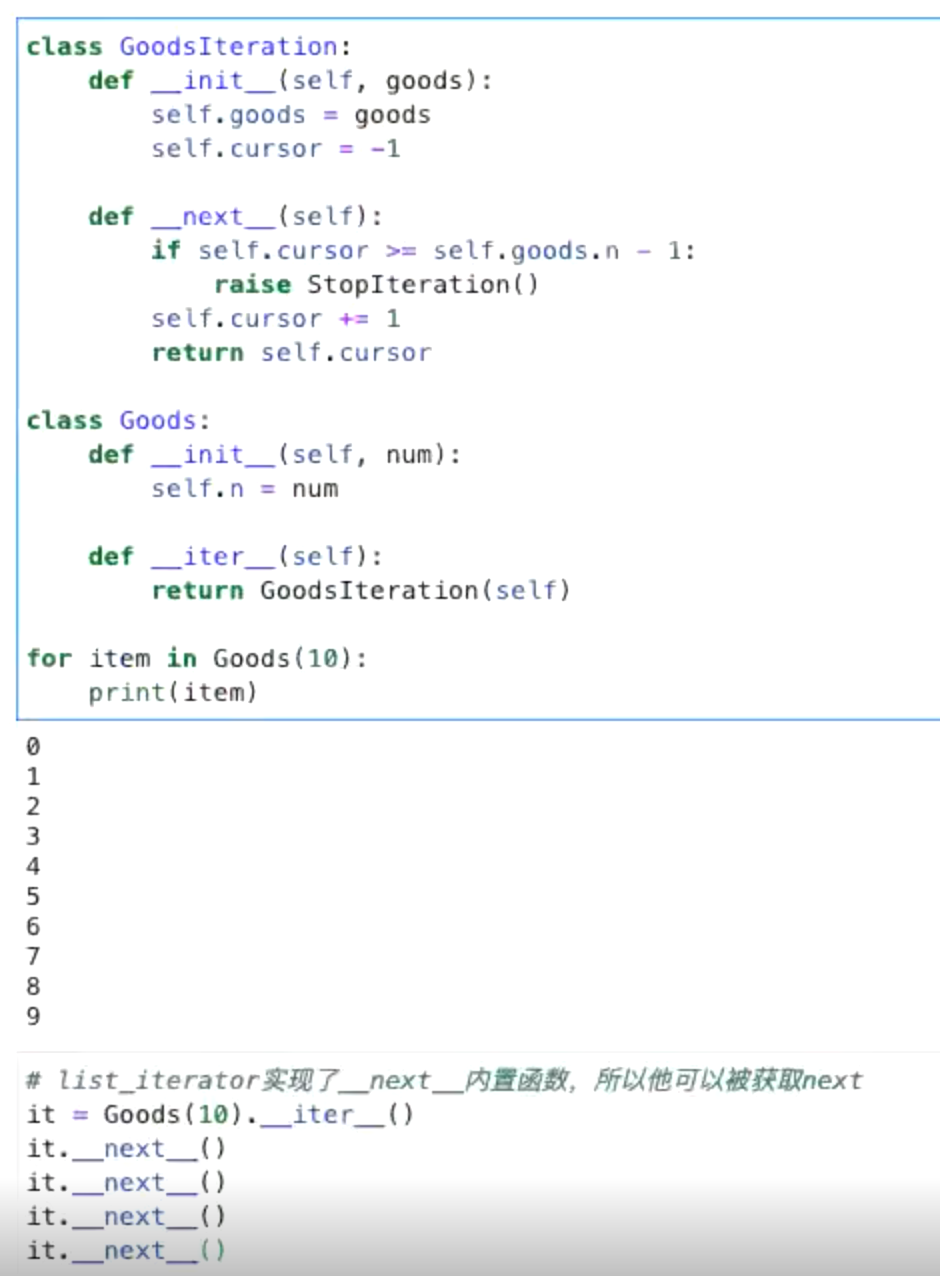 要实现自己的迭代器,其实就是要实现一个
要实现自己的迭代器,其实就是要实现一个__iter__()方法,返回一个迭代器,而__next__()方法是迭代器的方法,并不是在自身类里面去实现的方法。(所以你dir(list)是看不到数组的__next__()方法的
# 迭代时加索引需要enumerate一下
>>> arr = ['a','b','c']
>>> c = [f'{index}:{item}' for index, item in enumerate(arr)] # 其实就是解包(unpack)
zip
a = ['walker','jack','lucy']
b = [23,24,25]
c = ['male','male','female']
r = [f'{name}/{sex}/{age}' for name, age, sex in zip(a,b,c)]
# 其实就是每次从各个数组里抽一个元素出来组成一个tuple, 然后再解包
['walker/male/23', 'jack/male/24', 'lucy/female/25']
# 自己去测如果数组元素数量不一会怎样
# 加索引
for index, (name, age, sex) in enumerate(zip(a,b,c)):
print(f'{index},{name},{age},{sex}')
for i in range(1, 2):
for j in range(1, 2):
for k in range(0, 3):
for l in range(0, 3):
查看zip生成的中间状态用list, 但会消费掉zip生成的迭代器:
a = ('a', 'b')
b = (1, 2)
z = zip(a, b)
print(list(z)) # [('a', 1), ('b', 2)] - 查看中间状态
# ⚠️ 注意:list() 会消费掉迭代器
z = zip(a, b) # 需要重新创建
c = dict(z) # 才能正常工作
合并
from typing import Annotated
import operator
# 不同的合并策略示例
class StateExample(TypedDict):
# 列表追加合并 ([a]+[b] = [a,b])
steps: Annotated[List[str], operator.add]
# 字典更新合并
config: Annotated[dict, operator.or_]
# 替换合并(默认)
current_value: str # 新值直接替换旧值
# 数值累加
counter: Annotated[int, operator.add]
查找库位置
import ctypes.util;
print(ctypes.util.find_library('crypto'))
生成器和yield
def nest():
yield 1
v = yield 2
yield v
# 调用
n = nest()
print(next(n)) # 1
print(next(n)) # 2
print(n.send(3)) # 3
yield是一个双向表达式, 表示:
- 函数执行到这里, 会返回一个值, 并且暂停执行
- 下一轮激活的方式是
next()或send(value) - 接收到的值会传给
yeild表达式的左边的变量(赋值) - 然后执行后面的代码
next()等同于send(None)
理解的关键是这里: yield是停在赋值函数的右侧! 即发送值这一步, 然后就停在这里接收值. 接收到的值,如果写了赋值表达式, 就赋给左边的变量.
# 列表推导式:立即计算并存储所有值
lst = [i for i in range(3)]
print(lst) # [0, 1, 2] - 直接看到所有值
print(type(lst)) # <class 'list'>
# 生成器表达式:返回生成器对象,不立即计算
gen = (i for i in range(3))
print(gen) # <generator object <genexpr> at 0x...>
print(type(gen)) # <class 'generator'>
# 需要迭代才能取值
print(list(gen)) # [0, 1, 2] - 手动转换为列表
上下文管理器/with/contextlib
# 方式1:类实现
class FileManager:
def __init__(self, filename):
self.filename = filename
def __enter__(self):
self.file = open(self.filename)
return self.file
def __exit__(self, exc_type, exc_val, exc_tb):
self.file.close()
# 方式2:contextlib
from contextlib import contextmanager
@contextmanager
def file_manager(filename):
f = open(filename)
try:
yield f
finally:
f.close()
# 使用
with file_manager('test.txt') as f:
content = f.read()
这里面也用了yield,所以整个过程其实是这样的:
# 进入with时, 实例化, 并帮你跑第一个next()
gen = file_manager('test.txt')
f = next(gen)
# 拿到了文件句柄, 等待
# with里面其他的代码正常执行
# 退出with时, 会再调一次
next(gen)
# 这时候一定会抛出StopIteration异常, 然后with会捕获这个异常,
# 然后帮你跑finally里面的代码(即释放资源)
小结: 一切顺利的话, with最少调了两次 next,第二次一定触发 StopIteration, 这就是 Python 确保资源被清理的机制!
错!!!
with帮你调了next不假,但退出前是调的close,这有本质区别。close是通知生成器,你可以停止了,语义上是通知生成器。生成器内部会产生一个GeneratorExit异常,然后生成器会捕获这个异常,并执行finally里的代码。
而next的语义是“再给我一个值”,生成器没有值了,则会对外抛出StopIteration异常,自己是不会捕获的。
装饰器
- 装饰器的本质是把被装饰的函数变成一个新的函数(
wrapper).被装饰的函数前后可以执行一些额外的操作. - 装饰器的流程也就是先执行
@xxxx这段代码,入参就是@符号修复的这段代码
# 无参数装饰器
@decorator
def func(): pass
# 等价于:func = decorator(func)
# 带参数装饰器
@decorator("param")
def func(): pass
# 等价于:func = decorator("param")(func)
# 类装饰器
@Decorator("param")
def func(): pass
# 等价于:func = Decorator("param")(func)
其中, 普通装饰器是一个普通方法, 所以它是把wrapper在调用的时候返回:
def normal_decorator(func):
def wrapper():
func()
return wrapper
@normal_decorator
def hello(): pass # 等价于:hello = normal_decorator(hello)
而类装饰器则用了__call__()魔法函数(即对类实例直接调方法,而不是用方法名调方法), 所以把wrapper返在__call__()里即可:
class ClassDecorator:
def __init__(self, param):
self.param = param
def __call__(self, func):
def wrapper():
func()
return wrapper
@ClassDecorator("param")
def hello(): pass # 等价于:hello = ClassDecorator("param")(hello)
类装饰器
def singleton(cls):
_instances = {}
def get_instance(*args, **kwargs):
# 使用参数作为键的一部分?还是只用类作为键?
# 这里使用类作为键,所有参数相同的调用返回同一个实例
if cls not in _instances:
_instances[cls] = cls(*args, **kwargs)
return _instances[cls]
return get_instance
@singleton
class Config:
def __init__(self, env="dev"):
self.env = env
print(f"初始化配置: env={env}")
# 测试
c1 = Config("dev")
c2 = Config("dev")
c3 = Config("prod") # 注意:prod 参数也会返回 dev 实例
print(c1 is c2) # True
print(c1 is c3) # True - 还是同一个实例
print(c1.env) # dev
这个例子里,
- 对
Config类进行包装,等同于singleton(Config), - 然后返回一个
get_instance函数,- 这个函数会检查
_instances字典里有没有Config这个键, - 如果没有,就创建一个
Config实例,并把它放到字典里,下次再调用Config类时,直接返回字典里的实例
- 这个函数会检查
- 无论调用多少次,不管参数相不相同,都会返回同一个实例。
核心点:Config由class变成了function
print(Config) # <function singleton.<locals>.get_instance>
所以也可以理解为替换的是“构造函数”,而不是把类变成了函数。因为对类加括号进行调用,本来就是调用它的构造函数。
现在来解决如果构造函数入参不同,支持返回不同实例的问题:
def singleton(cls):
"""
更完善的单例:根据参数缓存不同的实例
"""
_instances = {} # 键为 (cls, args, kwargs) 的组合
def get_instance(*args, **kwargs):
# 创建缓存键
key = (cls, args, tuple(sorted(kwargs.items())))
# key = (cls, args, frozenset(kwargs.items())) # 也可以用 frozenset,比排序元组要快
if key not in _instances:
_instances[key] = cls(*args, **kwargs)
return _instances[key]
return get_instance
@singleton
class Database:
def __init__(self, host, port):
self.host = host
self.port = port
print(f"创建连接: {host}:{port}")
# 测试
db1 = Database("localhost", 3306)
db2 = Database("localhost", 3306)
db3 = Database("localhost", 3307)
print(db1 is db2) # True - 相同参数,同一实例
print(db1 is db3) # False - 不同参数,不同实例
浅拷贝和深拷贝
- 普通
copy是浅拷贝 - 它拷贝的是表层元素(即内存地址相同), 但容器本身是新建的(否则叫赋值)
- 如果元素本身是可变的(或者说是容器, 如列表, 字典, 集合), 你改变它里面的元素, 容器本身地址没变, 则数据源也会相应改变
- 如果元素本身是不可变的(数字, 字符串, 元组), 你改变了它等于指向了新地址,数据源不会变
import copy
original = [1, 2, [2,3,4], 3]
shallow = copy.deepcopy(original)
shallow[2][1] = 'changed'
print(id(original[0]))
print(id(shallow[0]))
这里用deepcopy还是copy只影响第三个元素, 是把[2,3,4]这个对象的地址拷过来了, 还是自己新建一个数组挨个把里面的元素复制过去.
- 如果是浅拷贝,那么数据源对应位置也变成了
changed - 如果是深拷贝,不影响
- 如果是
shallow[2] = 'changed', 那无论是深浅, 都不影响数据源, 因为指向的对象地址变了
动态属性
Python中,对实例可以添加任意属性,并且不需要声明(赋值就添加了),这就是动态属性。那么IDE是如何提示这些属性的呢?
- 高级IDE(如PyCharm)会根据代码上下文,自动推断出属性,并显示在代码提示中。
- 否则就靠你自己声明。是的,你也可以声明的。
在Python中, 你声明一个类属性的注解(光注解,不赋值),给类属性直接赋值(会推断类型),都能被推断出是类属性
class User:
name: str # 声明类属性
age: int # 声明类属性
def __init__(self, name: str, age: int):
self.name = name # 赋值,推断出实例属性
self.age = age # 赋值,推断出实例属性
上例中:
- 注解不是属性,但IDE会根据注解推断出属性.(不是属性的意思是不在
__dict__中) - 上例中,如果没有
self.name,self.age的赋值语句,那name和age就是类属性 - 在init中赋值后,就成了实例属性,这叫覆盖
__dict__与dir()的区别
class A:
a1 = 3
def __init__(self):
self.a2 = 4
print(A.__dir__) # {a1: 3}
print(A().__dir__) # {a2: 4}
# ✅ 推荐:明确声明属性
class User:
def __init__(self, name: str, age: int):
self.name: str = name # 类型注解 + 赋值
self.age: int = age
self.email: str = "" # 声明但稍后赋值
self._private: int = 0 # 私有属性
# ✅ 推荐:使用 dataclass
from dataclasses import dataclass
@dataclass
class Product:
id: int # 纯注解
name: str
price: float = 0.0 # 注解加赋值
tags: list[str] = None
# ✅ 推荐:使用 Pydantic(数据验证)
from pydantic import BaseModel
class Config(BaseModel):
debug: bool = False
port: int = 8000
host: str = "localhost"
正则
Search
- search是匹配到后存到对象里,通过
group()方法获取匹配到的内容 - 并且是匹配到就退出,不会全局匹配
- 所以它的结果永远只有一个(期望就是
group()) - 里面的分组信息也可以取,但是都是针对这个“第一个匹配到的结果”而言的
import re
s = "小明年龄18岁,工资10000元。"
res = re.search(r"(\d+).*?(\d+)", s)
print(res.group()) # 18岁,工资10000
print(res.group(1)) # 18
print(res.group(2)) # 10000
group()本质上是group(0),即整个表达式的匹配group(1)是第一个括号匹配到的内容,以此类推,表达式没有对应的括号就报IndexError- 如果后面还有"小李20岁,工资8000元",也是匹配不到的
FinadAll
- findall则是存到列表里。
- 全局匹配
res = re.findall(r"\d+", s)
print(res) # ['18', '10000']
Match
- match是从字符串开头匹配,如果开头不是匹配的内容,则返回None
- 相当于正则版的
startswith
res = re.match("小明", s)
print(res.group()) # 小明
对None调group()会报错(AttributeError)
中文
title = '你好,hello,世界'
pattern = re.compile(r'[\u4e00-\u9fa5]+')
result = pattern.findall(title)
print(result) # ['你好', '世界']
应用
提取html
html = "<html><h1>http://www.example.com</h1></html>"
# 移除html标签也是一种办法
res = re.sub(r"<.*?>", "", html)
print(res) # http://www.example.com
# 根据规则提
res = re.search(r"(\<.*?\>)(\<.*?\>)(?P<content>.*?)(\<.*?\>)(\<.*?\>)", html)
print(res.groups()) # ('<html>', '<h1>', 'http://www.example.com', '</h1>', '</html>')
print(res.group("content")) # http://www.example.com
res.group("content") 等同于 res.group(3)
随机数
import random
print(random.randint(1, 101)) # 38
print(random.choice(range(1,101))) # 47
print(100*random.random()) # 76.6325375238469
排序
使用lambda函数对list排序foo = [-5,8,0,4,9,-4,-20,-2,8,2,-4],输出结果为[0,2,4,8,8,9,-2,-4,-4,-5,-20],正数从小到大,负数从大到小.
因为有两个规则,用一个key来对比是不够的,因此用元组作key,第一个值用来比正负,第二个值,用来比绝对值大小
foo = [-5,8,0,4,9,-4,-20,-2,8,2,-4]
foo.sort(key=lambda x: (x<0, abs(x)))
print(foo) # [0, 2, 4, 8, 8, 9, -2, -4, -4, -5, -20]
Children
Backlinks